
DB

애플리케이션은 데이터를 주고받는 것이 주 목적입니다.
엔터프라이즈급 애플리켕션에서 정상적으로 로직이 동작하기 위해서는 데이터베이스(Database)가 필요합니다. 가장 널리 사용하는 마리아DB(Maria DB)를 예시로 Springboot의 애플리케이션에 연동해보겠습니다.
마리아DB(MariaDB) 다운로드 및 설치

Download MariaDB Server - MariaDB.org
REST API Release Schedule Reporting Bugs … Continue reading "Download MariaDB Server"
mariadb.org
해당 링크로 가서 마리아DB를 설치해줍니다.

원하는 버전의 서버를 선택해서 설치파일을 받습니다.
하단의 Mirror의 경우, 2022.09 이후로 Korea가 사라졌습니다. Taipei나 Japan같은 가까운 곳으로 선택해주면 됩니다.
만약 원하는 버전이 없다면, 'Display older releases' 라는 체크박스를 클릭해서 다운받을 수 있습니다.

다운받은 설치파일을 클릭해서 치를 진행하다가, 위처럼 DB의 root(관계형 데이터베이스 시스템에서 관리자 수준의 권한을 가진 사용자)의 패스워드를 지정해주고, 가장 대중적인 인코딩 방식인 UTF-8을 기본값으로 설정하기위해 해당 체크받스를 체크해줍니다.

이후 서버 이름과 포트 번호를 설정해야 합니다. 마리아DB는 기본 포트번호로 3306을 사용합니다.
이 부분은 건드릴 필요는 없습니다.
마리아 DB를 설치하면 서브파티 도구인 'HeidiSQL'이 함께 설치됩니다. HeidiSQL은 데이터베이스에 접속해서 관리하는 GUI도구로 사용하게 됩니다.

HeidiSQL을 실행하면 위처럼 세션관리자 창이 뜹니다.
우측 하단에 신규버튼을 누릅니다. 우리가 신경써야할 부분은 IP, 사용자, 암호, 포트 입니다.
- 호스트명/ip는 테스트를 위해서 localhost(127.0.0.1)으로 설정해줍니다.
- 사용자는 root로, 암호는 설치시에 설정했던 root의 암호를 입력합니다.
- 포트는 아무것도 건드리지 않았다면 마리아DB는 3306으로 설정되어 있습니다. 다른 경우 설치단계에서 확인한 포트를 입력합니다.
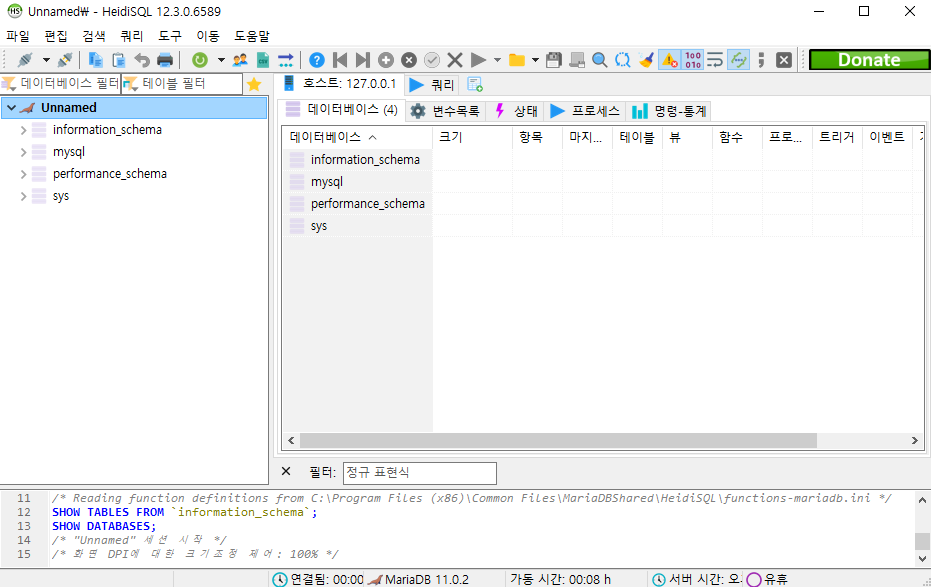
그럼 이렇게 DB에 접속할 수 있습니다.

위처럼 쿼리에서 원하는 쿼리문을 입력하고 상단에 실행버튼을 누르면 쿼리문이 실행됩니다.
위에서는 DB를 생성하는 쿼리문을 입력하니 왼쪽에 해당하는 DB가 생성된 것을 확인해 볼 수 있습니다.
JPA, ORM?

우리가 애플리케이션의 클래스는 DB의 테이블과 매핑하기 위해 만들어진 것이 아니므로 불일치가 존재합니다. 이것을 해결해 주는 것이 ORM입니다. ORM(Object Relational Mapping)은 객체 관계 매핑을 의미하며 관계형 데이터베이스의 테이블을 자동으로 매핑하는 방법입니다.
JPA(Java Persistence API)는 자바 진영의 ORM 기술 표준으로 채택된 인터페이스의 모음입니다. ORM이 큰 개념이라면, JPA는 더 구체화된 스펙을 포함합니다. JPA는 매커니즘은 내부적으로 JDBC를 사용합니다. JDBC는 개발자가 클래스안에서 직접 쿼리문을 쳐야 하는데, 이는 SQL에 의존하는 문제가 발생하고, 개발의 효율이 떨어집니다. JPA는 이러한 문제점을 보완해서 개발자 대신 SQL을 생성해서 객체를 자동으로 매핑해줍니다.

Hibernate
자바의 ORM 프레임워크로 JPA가 정의하는 인터페이스를 구현하고 있는 JPA 구현체 중 하나입니다.
Spring Data JPA
Spring Data JPA는 JPA를 편리하게 사용할 수 있도록 지원하는 스프링 하위 프로젝트 중 하나.
CRUD 처리에 필요한 인터페이스를 제공하며 Hibernate의 엔티티 매니져를 다루지 않고 Repository를
정의해서 쿼리를 동적으로 생성하는 방식으로 DB를 조작하빈다.
영속성 컨텍스트

영속성 컨텍스트(Persistence Context)는 애플리케이션과 데이터베이스 사이에서 엔티티와 레코드의 괴리를 해소하는 기능과 객체를 보관하는 기능을 수행합니다. 엔티티 객체가 영속성 컨텍스트에 들어오면 JPA는 엔티티 객체의 매핑 정보를 데이터베이스에 반영하는 작업을 수행합니다. 이처럼 엔티티 객체가 영속성 컨텍스트에 들어와 JPA의 관리 대상이 되는 시점부터는 해당 객체를 영속 객체(Persistence Objdct)라고 부릅니다.
엔티티 매니져
// SimpleJpaRepository의 EntityManager 의존성 주입 코드
public SimpleJpaRepository(JpaEntityInformation<T, ?> entityInformation, EntityManager entityManager) {
Assert.notNull(entityInformation, "JpaEntityInformation must not be null!");
Assert.notNull(entityManager, "EntityManager must not be null!");
this.entityInformation = entityInformation;
this.em = entityManager;
this.provider = PersistenceProvider.fromEntityManager(entityManager);
}엔티티 매니저(EntityManager)는 이름 그대로 엔티티를 관리하는 객체입니다. 엔티티 매니저는 데이터베이스에 접근해서 CRUD 작업을 수행합니다. Spring Data JPA를 사용하면 리포지토리를 사용해서 데이터베이스에 접근하는데, 실제 내부 구현체인 SImpleJpaRepository가 아래와 같이 리포지토리에서 엔티티 매니저를 사용하는 것을 알 수 있습니다.
<-- 엔티티 매니저 팩토리 사용을 위한 persistence.xml 파일 설정 -->
<peristence xmlns="http://xmlns.jcp.org/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/nx/persistence/persistence_2_1.xsd"
version="2.1">
<persistence-unit name="entity_manager_factory" transaction-type="RESOURCE_LOCAL">
<properties>
<property name="javax.persistence.jdbc.driver" value="org.mariadb.jdbc.Driver"/>
<property name="javax.persistence.jdbc.user" value="root"/>
<property name="javax.persistence.jdbc.password" value="password"/>
<property name="javax.persistence.jdbc.url" value="jdbc:mariadb://localhost:3306/springboot"/>
<property name="hiberante.dialect" value="org.hibernate.dialect.MariaDB103Dialect"/>
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql"" value="true"/>
</properties>
</persistence-unit>
</persistence>
엔티티 매니저는 엔티티 매니저 팩토리(EntityManagerFactory)가 만듭니다. 엔티티 매니저 팩토리는 데이터베이스에 대응하는 객체로서 스프링 부트에서는 자동 설정 기능이 있기 때문에 application.properties에서 작성한 최소한의 설정만으로도 동작하지만 JPA의 구현체 중 하나인 하이버네이트에서는 persistence.xml이라는 설정 파일을 구성하고 사용해야 하는 객체입니다.
엔티티 매니저 팩토리로 생성된 엔티티 매니저는 엔티티를 영속성 컨텍스트에 추가해서 영속 객체로 만드는 작업을 수행하고, 영속성 컨텍스트와 데이터베이스를 비교하면서 실제 데이터베이스를 대상으로 작업을 수행합니다.
엔티티의 생명주기
|
데이터베이스 연동
이전에 생성한 데이터베이스를 사용하기 위해서는 스프링 부트 애플리케이션과 연동해야 합니다.
프로젝트를 생성합니다
프로젝트 생성
| 프로젝트 옵션 SpringBoot : 2.5.6 추가 라이브러리 Developer Tools: Lombok, Spring Configuration Processor Web : Spring Web SQL : Spring Data JPA, MariaDB Driver Swagger 의존성을 pom.xml 파일에 추가 |
@Configuration
@EnableSwagger2
public class SwaggerConfiguration {
@Bean
public Docket api() {
return new Docket(DocumentationType.SWAGGER_2)
.apiInfo(apiInfo())
.select()
.apis(RequestHandlerSelectors.basePackage("com.springboot.jpa"))
.paths(PathSelectors.any())
.build();
}
private ApiInfo apiInfo() {
return new ApiInfoBuilder()
.title("Spring Boot Open API Test with Swagger")
.description("설명 부분")
.version("1.0.0")
.build();
}
}위처럼 SwaggerConfiguration 파일을 수정해줍니다.
// application.properties에 DB 관련 설정 추가
spring.datasource.driverClassName=org.mariadb.jdbc.Driver
spring.datasource.url=jdbc:mariadb://localhost:3306/springboot
spring.datasource.username=root
spring.datasource.password={패스워드}
spring.jpa.hibernate.ddl-auto=create
spring.jpa.show-sql=true
spring.jpa.properties.hibernate.format_sql=trueSpring Data JPA 의존성을 추가한 후에는 별도의 설정이 필요합니다. 즉, 애플리케이션이 정상적으로 실행될 수 있게 연동할 데이터베이스의 정보를 application.properties에 작성해야 합니다. 이 설정 없이는 스프링 부트 애플리케이션이 실행되지 않습니다.
| hibernate의 옵션 dll-auto : 데이터 베이스를 자동으로 조작하는 옵션입니다. create: 애플리케이션이 가동되고 SessionFactory가 실행될 때 기존 테이블을 지우고 새로 생성합니다. create-drop : create와 동일한 기능을 수행하나 애플리케이션을 종료하는 시점에 테이블을 지웁니다. update : SessionFactory가 실행될 때 객체를 검사해서 변경된 스키마를 갱신한다. 기존에 저장된 데이터는 유지됩니다. validate : update처럼 객체를 검사하지만 스키마는 건드리지 않습니다. 검사 과정에서 데이터베이스의 테이블 정보와 객체의 정보가 다르면 에러가 발생합니다. none : ddl-auto 기능을 사용하지 않습니다. |
운영 환경에서는 create, create-drop, update 기능은 사용하지 않습니다.
데이터베이스에 축적된 데이터를 지워버릴 수도 있고, 사람의 실수로 객체 정보가 변경됐을 때 운영 환경의 데이터베이스 정보까지 변경될 수 있기 때문입니다. 운영 환경에서는 대체로 validate나 none을 사용합니다. 반면 개발 환경에서는 create 또는 update를 사용합니다. 이번에는 개발환경을 연습하는 부분이므로 create를 사용합니다.
엔티티 설계

Spring Data JPA를 사용하면 데이터베이스에 테이블을 생성하기 위해 직접 쿼리를 작성할 필요가 없습니다. 이 기능을 가능하게 하는 것이 엔티티입니다. JPA에서 엔티티는 데이터베이스의 테이블에 대응하는 클래스입니다. 엔티티에는 데이터베이스에 쓰일 테이블과 칼럼을 정의합니다. 엔티티에 어노테이션을 사용하면 테이블 간의 연관관계를 정의할 수 있습니다. 위와같은 예제를 엔티티 클래스로 생성합니다.
package com.springboot.jpa.data.entity;
import java.time.LocalDateTime;
import javax.persistence.*;
@Entity
@Table(name = "product")
public class Product {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long number;
@Column(nullable = false)
private String name;
@Column(nullable = false)
private Integer price;
@Column(nullable = false)
private Integer stock;
private LocalDateTime createdAt;
private LocalDateTime updatedAt;
... getter/setter 메서드
}
위와 같이 클래스를 생성하고 코드를 작성하면 쿼리문을 작성하지 않아도 데이터베이스에 테이블이 자동으로 만들어집니다.
엔티티 관련 기본 어노테이션
@Entity
해당 클래스가 엔티티임을 명시하기 위한 어노테이션입니다. 클래스 자체는 테이블과 일대일로 매칭되며, 해당 클래스의 인스턴스는 매핑되는 테이블에서 하나의 레코드를 의미합니다.
@Table
엔티티 클래스는 테이블과 매핑되므로 특별한 경우가 아니면 @Table 어노테이션이 필요하지 않습니다. @Table 어노테이션을 사용할 때는 클래스의 이름과 테이블의 이름을 다르게 지정해야 하는 경우입니다. @Table 어노테이션을 명시하지 않으면 테이블의 이름과 클래의 이름이 동일하다는 의미이며, 서로 다른 이름을 쓰려면 @Table(name = 값) 형태로 데이터베이스의 테이블명을 명시해야 한다. 대체로 자바의 명명법과 데이터베이스가 사용하는 명명법이 다르기 때문에 자주 사용됩니다.
@Id
엔티티 클래스의 필드는 테이블의 칼럼과 매핑됩니다. @Id 어노테이션이 선언된 필드는 테이블의 기본값 역할로 사용됩니다. 모든 어노테이션에서는 @Id어노테이션이 필요합니다.
@GeneratedValue
일반적으로 @Id 어노테이션과 함께 사용됩니다. 이 어노테이션은 해당 필드의 값을 어떤 방식으로 자동으로 생성할지 결정할 때 사용합니다. 값 생성 방식은 아래와 같습니다.
GeneratedValue를 사용하지 않는 방식(직접 할당)
- 애플리케이션에서 자체적으로 고유한 기본값을 생성할 경우 사용하는 방식입니다.
- 내부에 정해진 규칙에 의해 기본값을 생성하고 식별자로 사용합니다.
AUTO
- @GeneratedValue의 기본 설정값
- 기본값을 사용하는 데이터베이스에 맞게 자동 생성합니다.
IDENTITY
- 기본값 생성을 데이터베이스에 위임하는 방식입니다.
- 데이터베이스의 AUTO_INCREMENT를 사용해 기본값을 생성합니다.
SEQUENCE
- @SequenceGenerator 어노테이션으로 식별자 생성기를 설정하고 이를 통해 값을 자동 주입받습니다.
- SequenceGenerator를 정의할 때는 name, sequenceName, allocationSize를 활용합니다.
- @GeneratedValue에 생성기를 설정합니다.
Table
- 어떤 DBMS를 사용하더라도 동일하게 동작하기를 원할 경우 사용합니다.
- 식별자로 사용할 숫자의 보관 테이블을 별도로 생성해서 엔티티를 생성할 때마다 값을 갱신하며 사용합니다.
- @TableGenerator 어노테이션으로 테이블 정보를 설정합니다.
@Column
엔티티 클래스의 필드는 자동으로 테이블 칼럼으로 매핑됩니다. 그래서 별다른 설정을 하지 않을 예정이라면 이 어노테이션을 명시하지 않아도 됩니다. @Column은 필드에 몇 가지 설정을 더할 때 사용한다. @Column 어노테이션에서 많이 사용하는 요소는 아래와 같습니다.
- name : 데이터베이스의 칼럼명을 설정하는 속성입니다. 명시하지 않으면 필드명으로 지정됩니다.
- nullable : 레코드를 생성할 때 칼럼 값에 null 처리가 가능한지를 명시하는 속성입니다.
- length : 데이터베이스에 저장하는 데이터의 최대 길이를 설정합니다.
- unique : 해당 칼럼을 유니크로 설정합니다.
@Transient
- 엔티티 클래스에는 선언돼 있는 필드지만 데이터베이스에서는 필요 없을 경우 이 어노테이션을 사용해 데이터베이스에서 이용하지 않게 할 수 있습니다.
리포지토리 인터페이스 설계
Spring Data JPA는 JpaRepository를 기반으로 더욱 쉽게 데이터베이스를 사용할 수 있는 아키텍처를 제공합니다. 스프링 부트로 JpaRepository를 상속하는 인터페이스를 생성하면 기존의 다양한 메서드를 손쉽게 활용할 수 있습니다.
리포지토리(Repository)는 Spring Data JPA가 제공하는 인터페이스입니다. 엔티티를 데이터베이스의 테이블과 구조를 생성하는 데 사용했다면 리포지토리는 엔티티가 생성한 데이터베이스에 접근하는 데 사용합니다.
리포지토리를 생성하기 위해서는 접근하려는 테이블과 매핑되는 엔티티에 대한 인터페이스를 생성하고 JpaRepository를 상속받으면 됩니다.
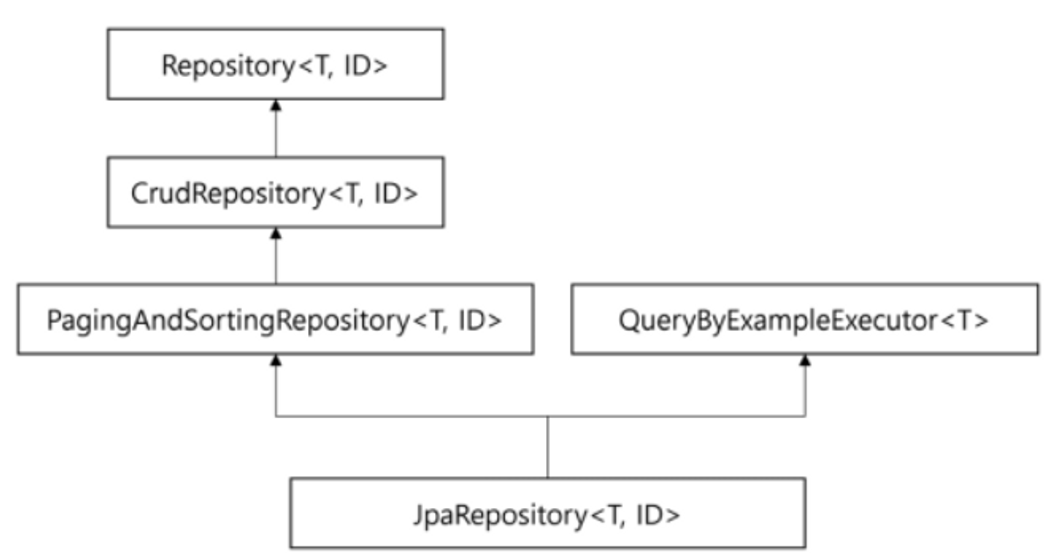
JpaRepository의 상속 구조를 보면 위와 같습니다.
리포지토리 메서드의 생성규칙
리포지토리 메서드 생성 규칙은 다음과 같습니다:
- FindBy: SQL 문의 where 절 역할을 수행하는 구문입니다. "findBy" 뒤에 엔티티의 필드값을 입력해서 사용합니다. AND, OR: 조건을 여러 개 설정하기 위해 사용합니다.
- Like/NotLike: SQL 문의 like와 동일한 기능을 수행하며, 특정 문자를 포함하는지 여부를 조건으로 추가합니다. 비슷한 키워드로 Containing, Contains, isContaining이 있습니다.
- StartsWith/StartingWith: 특정 키워드로 시작하는 문자열 조건을 설정합니다.
- EndsWith/EndingWith: 특정 키워드로 끝나는 문자열 조건을 설정합니다.
- IsNull/IsNotNull: 레코드 값이 Null이거나 Null이 아닌 값을 검색합니다.
- True/False: 타입의 레코드를 검색할 때 사용합니다.
- Before/After: 시간을 기준으로 값을 검색합니다.
- LessThan/GreaterThan: 특정 값(숫자)을 기준으로 대소 비교를 할 때 사용합니다.
- Between: 두 값(숫자) 사이의 데이터를 조회합니다.
- OrderBy: SQL 문에서 "order by"와 동일한 기능을 수행합니다.
- CountBy: SQL 문의 "count"와 동일한 기능을 수행하며, 결과값의 개수(count)를 추출합니다.
DAO 설계
DAO(Data Access Object)는 데이터베이스에 접근하기 위한 로직을 관리하기 위한 객체입니다.
비즈니스 로직의 동작 과정에서 데이터를 조작하는 기능은 DAO 객체가 수행합니다. 그러나 스프링 데이터 JPA에서는 DAO의 개념이 리포지토리로 대체되었습니다. 규모가 작은 서비스에서는 DAO를 별도로 설계하지 않고 바로 서비스 레이어에서 데이터베이스에 접근하여 구현하기도 합니다. 하지만 현재는 DAO를 서비스 레이어와 리포지토리의 중간 계층으로 사용할 예정입니다.
실제로 업무에 필요한 비즈니스 로직을 개발하다 보면 데이터를 다루는 중간 계층을 두는 것이 유지보수 측면에서 용이한 경우가 많습니다.
서비스 레이어에서 리포지토리의 메서드를 호출하고 그 결과에 대해 처리할 수 있지만, 비즈니스 로직을 수행하는 과정에서 데이터베이스 관련 작업을 처리하는 것은 기능을 분리하고 관리하기에 좋은 코드라고 보기는 어렵습니다.
DAO 클래스 생성
DAO 클래스는 일반적으로 ‘인터페이스-구현체’ 구성으로 생성합니다. DAO 클래스는 의존성 결합을 낮추기 위한 디자인 패턴이며, 서비스 레이어에 DAO 객체를 주입받을 때 인터페이스를 선언하는 방식으로 구성할 수 있습니다.
일반적으로 데이터베이스에 접근하는 메서드는 리턴 값으로 데이터 객체를 전달합니다. 이때 데이터 객체를 엔티티 객체로 전달할지, DTO 객체로 전달할지에 대해서는 개발자마다 의견이 다릅니다. 일반적인 설계 원칙에서 엔티티 객체는 데이터베이스에 접근하는 계층에서만 사용하도록 정의합니다. 다른 계층으로 데이터를 전달할 때는 DTO 객체를 사용합니다.
DAO 연동을 위한 컨트롤러와 서비스 설계
설계한 구성 요소들을 클라이언트의 요청과 연결하려면 컨트롤러와 서비스를 생성해야 합니다. 이를 위해 먼저 DAO의 메서드를 호출하고 그 외 비즈니스 로직을 수행하는 서비스 레이어를 생성한 후 컨트롤러를 생성합니다.
롬복(Lombok)
롬복(Lombok)은 데이터(모델) 클래스를 생성할 때 반복적으로 사용하는 getter/setter 같은 메서드를 어노테이션으로 대체하는 기능을 제공하는 라이브러리입니다. 자바에서 데이터 클래스를 작성하면 대개 많은 멤버 변수를 선언하고, 각 멤버 변수별로 getter/setter 메서드를 만들어 코드가 길어지고 가독성이 낮습니다. 인텔리제이 IDEA나 이클립스 같은 IDE에서는 이러한 메서드를 자동으로 생성하는 기능을 제공하긴 하지만 가독성이 떨어진다는 점에서는 마찬가지입니다.
이럴때 롬복을 활용하면 다음과 같은 장점이 있습니다.
- 어노테이션 기반으로 코드를 자동 생성하므로 생산성이 높아집니다.
- 반복되는 코드를 생략할 수 있어 가독성이 좋아집니다.
- 롬복을 안다면 간단하게 코드를 유추할 수 있어 유지보수에 용이합니다.
이렇게 롬복은 어노테이션 기반으로 코드가 자동 생성된다는 장점이 있지만, 동시에 메서드를 개발자의 의도대로 정확하게 구현하지 못하는 경우가 발생하는 단점이 공존합니다.
롬복의 주요 어노테이션
- @Getter, @Setter
클래스에 선언돼 있는 필드에 대한 getter/setter 메서드를 생성합니다.
- 생성자 자동 생성 어노테이션
데이터 클래스의 초기화를 위한 생성자를 자동으로 만들어주는 어노테이션은 세 가지가 있습니다.
- NoArgsConstructor : 매개변수가 없는 생성자를 자동 생성합니다.
- AllArgsConstructor : 모든 필드를 매개변수로 갖는 생성자를 자동 생성합니다.
- RequiredArgsConstructor : 필드 중 final이나 @NotNull이 설정된 변수를 매개변수로 갖는 생성자를 자동 생성합니다.
- @ToString
이름 그대로 toString() 메서드를 생성하는 어노테이션이다. toString() 메서드는 필드의 값을 문자열로 조합해서 리턴합니다. 또한 민감한 정보처럼 숨겨야 할 정보가 있다면 @ToString 어노테이션이 제공하는 exclude 속성을 사용해 특정 필드를 자동 생성에서 제외할 수 있습니다.
- @EqualsAndHashCode
@EqualsAndHashCode는 객체의 동등성(Equality)과 동일성(Identity)을 비교하는 연산 메서드를 생성합니다.
- equals : 두 객체의 내용이 같은지 동등성을 비교합니다.
- hashCode : 두 객체가 같은 객체인지 동일성을 비교합니다.
- @Data
@Data는 앞서 설명한 @Getter/@Setter, @RequiredArgsConstructor, @ToString, @EqualsAndHashCode를 모두 포괄하는 어노테이션입니다. 앞서 설명한 어노테이션에서 생성하는 대부분의 코드가 필요하다면 @Data 어노테이션으로 앞에서 설명한 코드를 전부 한 번에 생성할 수 있습니다.
'Backend > Spring Boot' 카테고리의 다른 글
| Spring Boot - Spring Data JPA 활용 (0) | 2023.07.29 |
|---|---|
| Spring Boot - API를 작성하는 다양한 방법 (0) | 2023.07.23 |
| Spring boot - VScode로 시작하기 (0) | 2023.07.16 |
| Spring Boot 개발에 앞서 알면 좋은 기본 지식 (2) | 2023.07.08 |
| 스프링 부트(Spring boot)란? (0) | 2023.07.08 |